

AI x Creators:Pushing Creative Abilities to the Next Level — 4つのステップで考えるAIと音楽クリエイションの関係|CFD-007:光藤祐基
東京大学とソニーグループが共同で運営するCreative Futurists Initiative(以下CFI、越境的未来共創社会連携講座)は、異なる領域を越えて未来の共創をリードする方々を迎える対話の場「Creative Futurists Dialogues」シリーズ(以下CFD)を展開しています。第7回目のゲストはSony AIのCorporate Distinguished Engineer、光藤祐基さんです。
光藤さんは、AIが音楽クリエイションにどのように活用されるかを四つのステップに分けて解説し、AIとクリエイターの関係について具体的な事例を交えながら紹介しました。また、クリエイターの表現力を引き上げるために必要な要素についてもレクチャーしていただきました。後半では、4ステップ全てを網羅したユースケースの紹介と、AIからクリエイターを守る方法について議論しました。
(※) 記事中の所属・役職等は取材当時のもの
TEXT: Haruna Mori
PHOTOGRAPH: Yasuaki Kakehi Laboratory
PRODUCTION: VOLOCITEE Inc.

小薮:こんにちは、ソニーの小薮です。東大と共同で行っているこの講座のソニー側事務局を担当しています。本日はソニーから光藤に登壇してもらいます。このダイアログシリーズは今回で7回目になります。1回目から6回目までは筧先生をはじめ、アート系の方々の登壇が多かったのですが、7回目にして初回以来のソニーからの登壇となります。工学寄りの内容になるため、今までとは異なるお話ができると思います。
光藤は2004年にソニーに入社し、2011年にはパリのフランス国立音響音楽研究所(IRCAM)の客員研究員として音楽とAIの分野に取り組み始めました。その後日本に戻り、様々なプロダクトや技術開発に携わってきました。多くの成果を上げており、ソニーの持続的成長のために技術戦略の策定や推進、人材の成長支援を行う技術者をCorporate Distinguished Engineerとして認定する制度の数少ない認定者の一人です。現在は仕事の関係でニューヨークに赴任しています。それでは、早速お話を伺いましょう。

光藤:よろしくお願いします。日曜日に来たばかりで時差ボケ中ですが、今日のアジェンダについてお話します。AIがクリエイションにどのように活用されるかを4つのステップに分けて、具体的な事例を紹介します。また、4ステップすべてを網羅したユースケースを2つ用意しており、紹介後にはクリエイターをAIから守る方法についてもお話しします。私たちはR&Dなので、多くの論文を発表していますが、リファレンスの中で自分たちのものをわかりやすくアスタリスクで示しています。他は一般的なものとして区別しています。
今まで関わってきたゲームタイトルにはいくつか音の技術があります。その中の一つが「グランツーリスモ」というゲームのエンジン音を生成する技術です。左のスライド内の写真は分かりづらいですが、ブルーレイディスクの6本入りボックスでもAI技術を使用しています。右はソニー・ミュージックエンタテインメントから出ているアルバムで、こちらもAI技術を活用しています。特に右のものは、今日のユースケースで取り扱う予定のものです。

先ほど小薮からも話がありましたが、ソニーにはCorporate Distinguished Engineerという制度があり、毎年約40人が選ばれています。全員が掲載されているウェブサイトもありますので、興味があればご覧ください。
Development AI for Creation
AI for Creationについてお話ししていますが、背景をご存知ない方も多いと思いますので、基本的なところから始めます。現在、第3次AIブームの時代で、AIと言った場合、広範囲にわたる多くのものを指しますが、ここでは主に深層学習をAIとして捉え、話を進めます。

クリエイターが使用するAIは制作に直結するイメージが強いですが、実際には「Understanding」と呼ばれる技術が中心です。これはAIがコンテンツを理解し、その情報を基に人がクリエイションを行う共創の形です。
「Conversion」はテキストのようなセマンティック情報を挟まずに直接別の形に変換する技術で、一番下の「Sound Separation」は混ざった音を分離する技術です。これらはリミキシングやリマスタリングなど、新しいバージョン作成時にも活用されています。
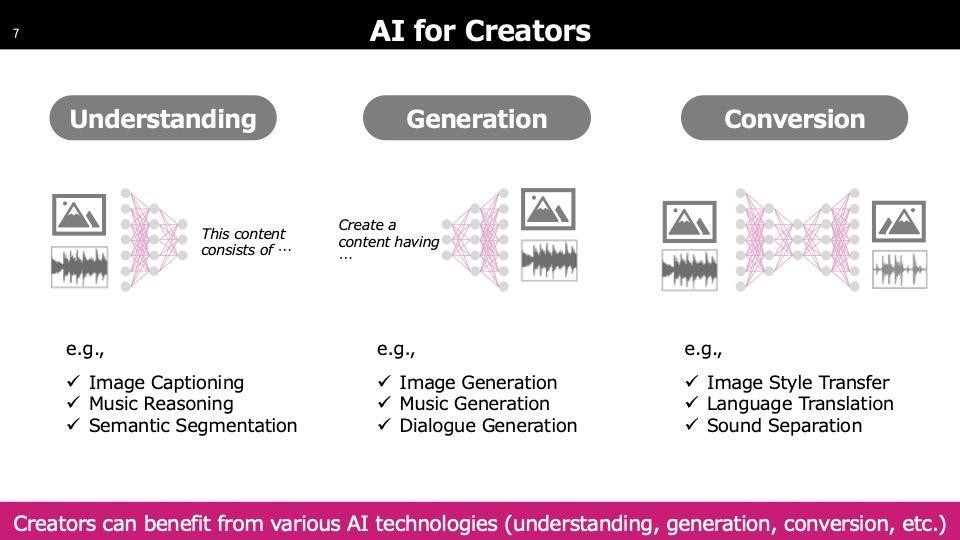
これは基本的に大量のデータとGPUを使用して大規模に学習します。使用時には、クリエイターの方々がコマンドプロンプトを扱うことが少ないため、軽量なモデルとして提供したり、クラウド上のモデルにアクセスして直感的に操作できるようにしています。これが一般的な方法です。

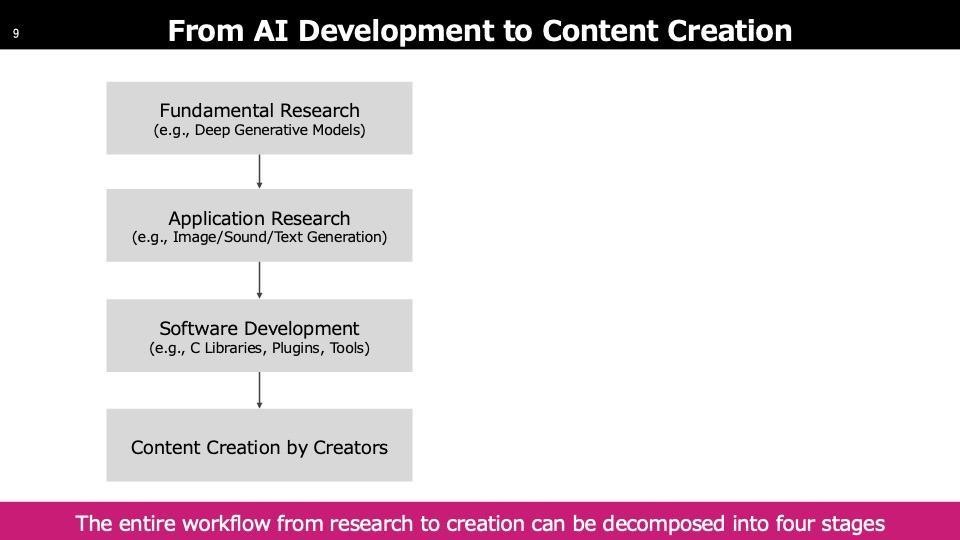
こちらは研究開発からクリエイションに至るまでの4ステージで、上の二つは研究段階です。コアな研究からクリエイションに関連する応用領域の研究があり、その後クリエイターに提供するエンジニアリングステップがあります。最後に、クリエイションでツールが使用され何かが作り上げられます。これらをステップに分けて、本日は説明します。
ステップ1: Fundamental Research(基礎研究)
まず最も取っ付き難いテーマですが、生成AIの基盤となる技術群についてです。「Diffusion」という言葉を聞いたことがあるかもしれませんが、生成AIの生成モデルのいくつかを簡単に紹介します。新しい生成モデルを開発することで、生成AI自体の性能が向上します。このFundamental Researchでの進展が、アプリケーションリサーチの性能向上につながる流れだと考えています。リサーチが性能向上に繋がるみたいな流れだと思っていただければと思います。
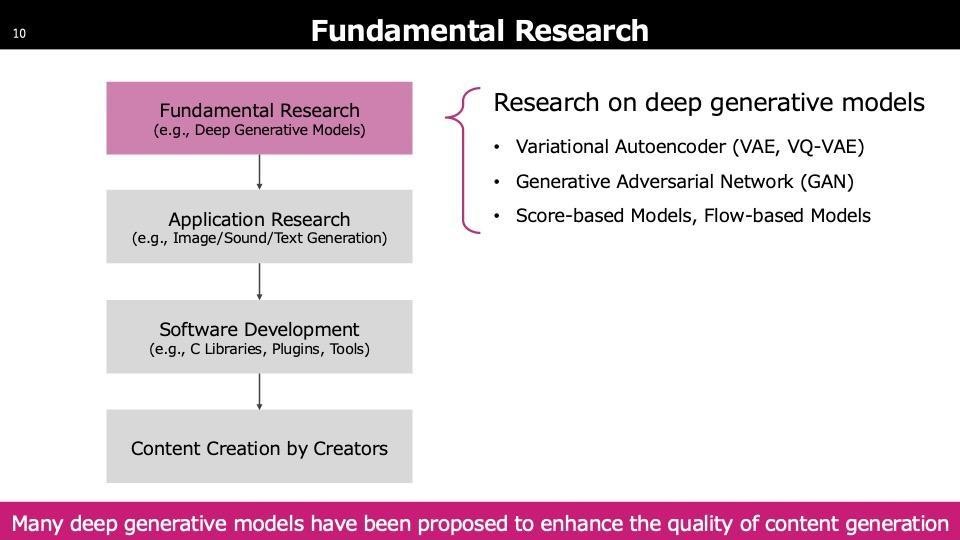
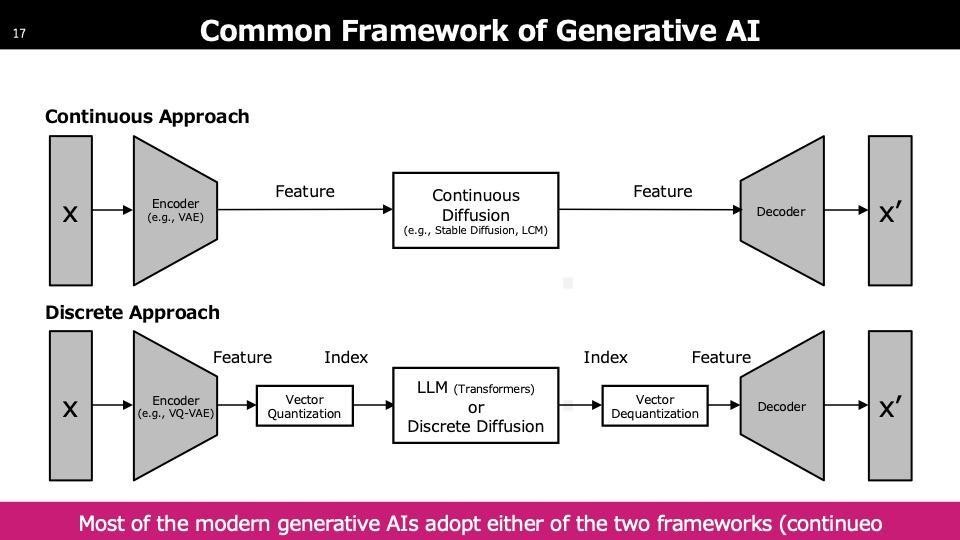
ステップ1には、主に三つの生成モデルが多く見られます。一つ目はVAE(Variational Auto Encoder)で、主に情報の圧縮に使われていますが、生成AIのコアとしてはあまり使用されていません。二つ目はGAN(Generative Adversarial Network)で、2020年頃までは画像生成の主流モデルでした。最近ではDiffusionというモデルが登場し、現在の論文ではほとんどDiffusionが使用されています。StableDiffusionというモデルもこのDiffusionからインスパイアされています。三つのモデルにはそれぞれ長所と短所があります。VAEの短所は出力がぼやける点で、画像が繊細さに欠けます。GANはクオリティが非常に高いですが、学習が難しく多くのテクニックを要します。Diffusionはクオリティが高く学習も安定していますが、生成速度が遅いです。スライドにも「Slow Sampling」とあります。Diffusionは多数のイテレーションを必要とするため、非常に遅くなるという欠点があり、これがボトルネックとなっています。
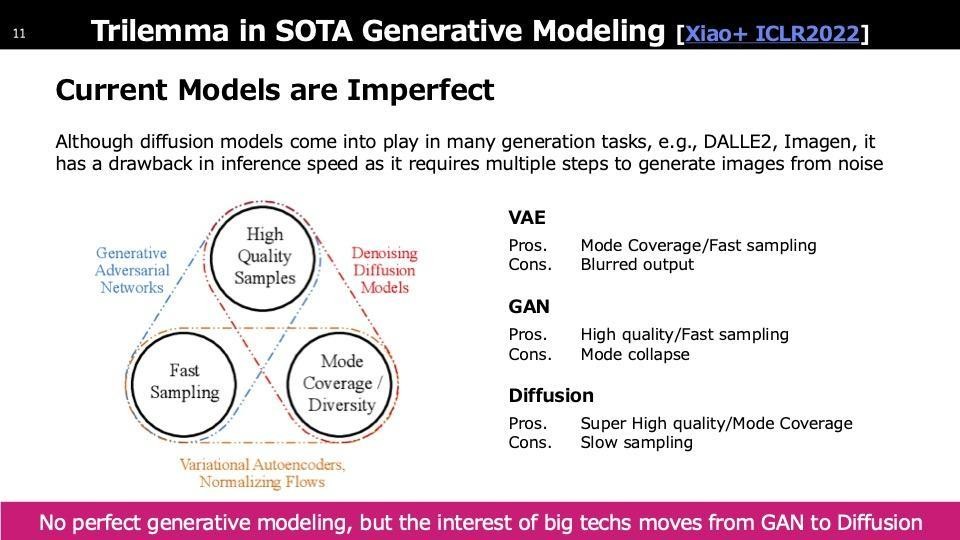
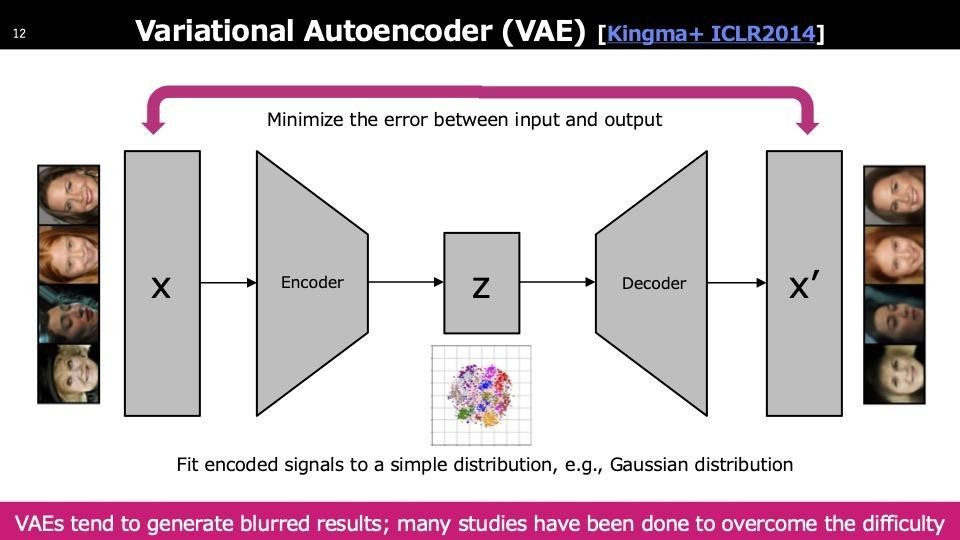
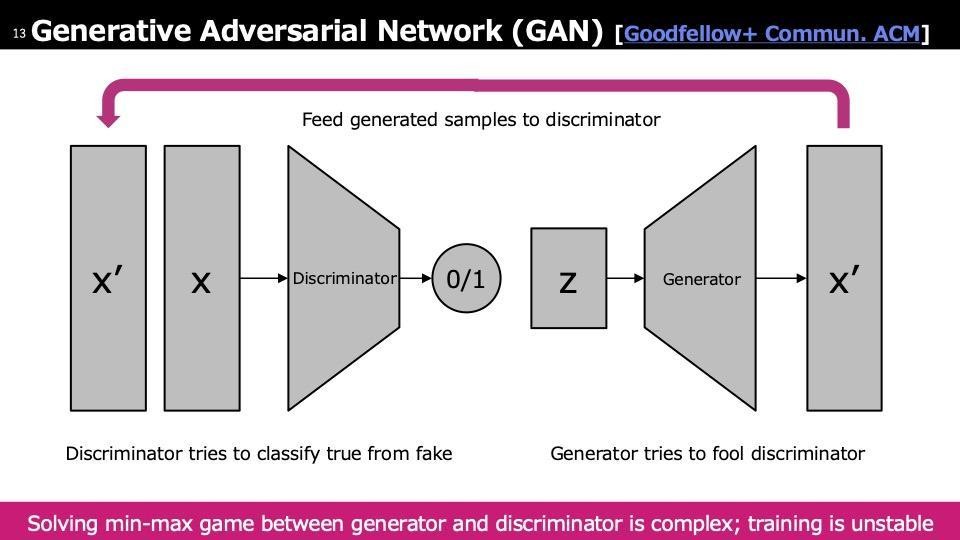
各生成モデルについて簡単に触れると、まずVAE(Variational Auto Encoder)についてです。VAEは学習データを潜在空間にマッピングし、再構築時に出力と入力のピクセル誤差を最小化する圧縮モジュールを学習します。学習が完了すると、潜在空間からサンプリングしたベクトルをデコーダーに通すことで画像が生成されます。次にGAN(Generative Adversarial Network)ですが、VAEと似た構造を持ちながらも異なります。GANではまず潜在空間Zでサンプリングし、未学習のジェネレーターを通して生成データX′を得ます。得られたX′と実際のサンプルXをDiscriminatorに入力して学習を行います。
このDiscriminatorは本物か偽物かを判別するモジュールで、Discriminatorを混乱させるようにGeneratorを学習するのがGANの仕組みです。学習が難しいのは、Discriminatorが最初から学習されていれば比較的簡単ですが、初期状態ではGeneratorもDiscriminatorも学習されていないため、これらを交互に学習していくのが非常に難しく、GANの問題点として学習がしづらいという点があります。
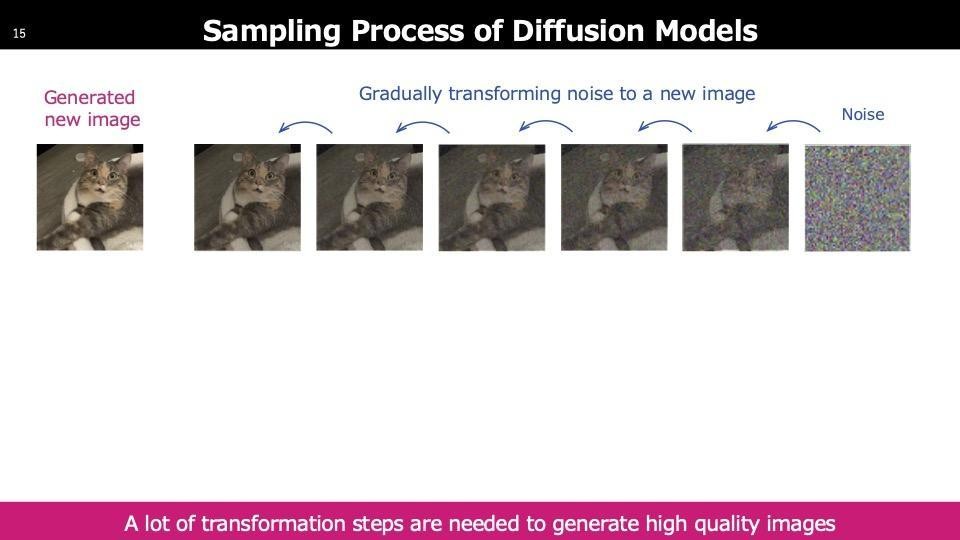
最後に、Diffusionについてです。Diffusionでは、トレーニング画像に徐々にノイズを加え、最終的には単なるノイズ状態にします。そのノイジーな画像から元の画像を復元するネットワークを学習します。サンプリング生成時には、初期のノイズ状態から開始し、選んだベクトルを徐々にノイズ除去して最終的に画像を生成します。このプロセスには多くのステップが必要なため、処理が重くなります。

これに対して、高解像度の画像に同様の処理を行うと、同じ次元間のマッピングが必要になるため、画像の次元が高くなるにつれてマッピング時間が増加します。そこで、より小さい空間でマッピングを行い、最後に元の次元に戻すことで効率を向上させる提案があります。この際、先ほどの圧縮モジュールであるVAEが使用されます。つまり、VAEは生成モデルとしてではなく、圧縮のために利用され、圧縮された空間でDiffusionを使用するパターンが一般的です。

先ほどの内容をまとめます。上部では、入力Xに対してVAEのエンコーダーを適用し、圧縮された空間でDiffusionを学習します。学習が完了するとサンプリングを行い、意味のあるものが生成されたらデコーダーを通してx′をリアルな画像に近づけます。上部と下部の違いについてですが、以前会社から「DiffusionとTransformerのどちらが良いのか」という質問を受けました。DiffusionとTransformerは現在、DiffusionTransformerという技術として存在しています。Diffusionは生成AIのフレームワークを指し、Transformerはネットワークの構造を指します。両者は共存可能であり、現在はDiffusionTransformerが利用されています。
Transformer自体は多くの言語モデルで使用されており、その構造が採用されています。真ん中に書かれているLLM(大規模言語モデル)はその一例です。画像にもLLM、つまりTransformerを使用できます。画像とテキストの違いは、データが離散的か連続的な数値で表現されるかです。下部のケースでは、離散化するステップが一つ含まれています。これら二つの技術が存在することを知っていただければと思います。
今日は時間がないですし、話の主眼になってくるところは応用寄りなところかなと思うので話さないのですが、我々は結構ここをやっていて今絶賛開催中のNeurIPS(ニューリップス)いう学会や、よくマシンラーニングの三大学会と呼ばれてるところにも出しています。
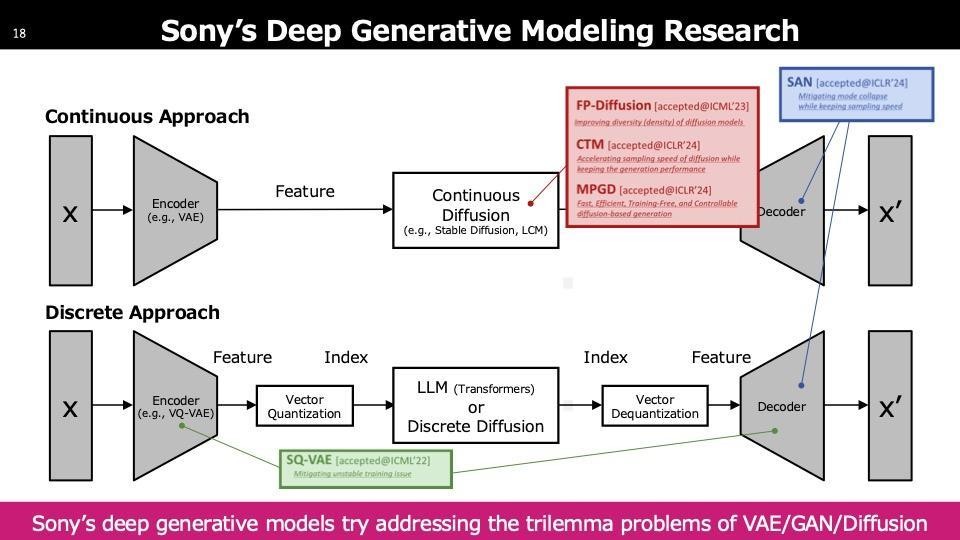
時間がないため、二つだけご紹介します。Diffusionは多くのステップを要し、例えば左側の猫の画像が生成されるまでに40ステップかかります。一方、スタンフォード大学と共同で開発したCTMは、ワンステップでクリアな画像を生成できます。これにより、迅速な出力が可能となり、インタラクティブなユースケースにも今後利用できる技術になると考えています。

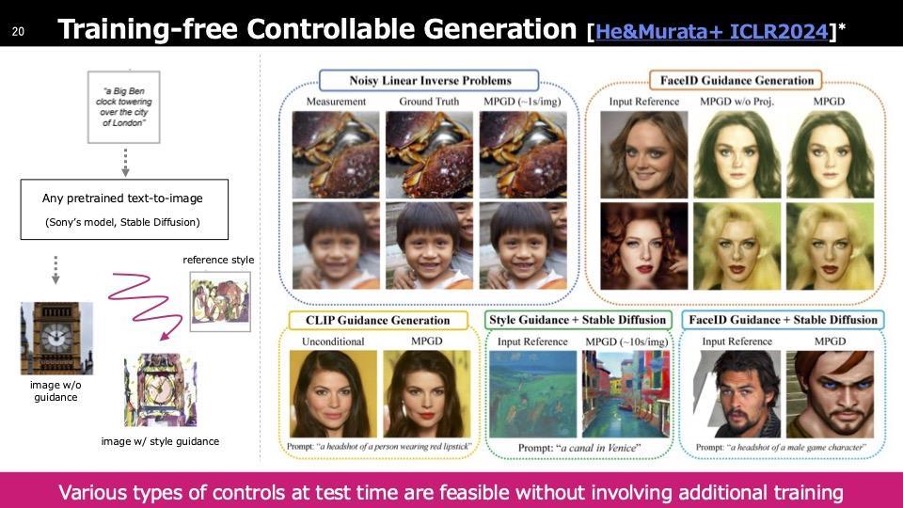
もう一つの技術として、トレーニングフリーで学習を必要としないコントローラブルな生成、技術用語ではGuided Diffusionと呼ばれています。これは、左側の図でStable Diffusionなどのモデルを使用し、上部のプロンプトに入力すると、左下のビッグ・ベンの画像が生成されます。再学習を行わずに、Reference Styleと記載されたスタイルに合わせた出力を提供する技術を開発しています。
左の例はリファレンススタイルですが、他にもInverse Problem(逆問題)と呼ばれる技術もあります。これは、既に失われた情報を復元する処理に使用でき、ぼやけた画像を参照画像として与えると、最終的にクリアな画像を生成します。
ステップ2:Application Research(応用研究)
ここまでがコアな機械学習の話でした。これらの知見や情報を活用して、実際のアプリケーション開発を行います。本日はMusic、Cinematic、Gameの三つの領域で、興味深い技術をピックアップしました。ほとんどが当社の関連技術です。

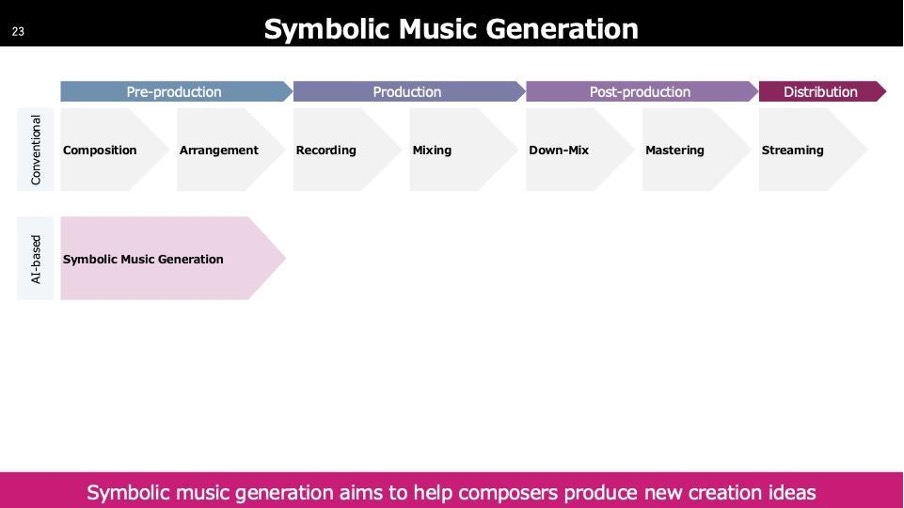
音楽のクリエイションプロセスは以下の流れです。一番左に「Composition」とあり、作曲や作詞を行います。これは専門の人が担当します。次に「Arrangement」として編曲を行い、曲自体が完成します。完成した曲は、歌ってもらったり演奏してもらう段階が必要で、その際「Recording」の作業に入ります。Recordingでは、人が声を入れたり、最近では初音ミクなどの音を加えます。録音した音は「Mixing」で、音の配置を最適化します。次に「Down-mix」や「Mastering」は、配信に向けたフォーマットの調整を行います。主流はまだ2チャンネルですが、5.1チャンネルやイマーシブなフォーマットも存在します。「Down-Mix」はこれらのフォーマットへの変換です。Masteringでは、連続で楽曲を流した際に楽曲間の聞こえ方の違いを調整します。Streamingについては説明を省略します。
これらのプロセスには多くのAI技術が関与しており、まず「Symbolic Music Generation」があります。これは作曲を支援するAI技術です。
若干古いのですが、2017年から作曲の分野でAIが研究されてきました。その順番でお話していきます。

DeepBachと呼ばれてるものでバッハの作曲を再現するような技術です。
次はRecordingの段階のときの使う技術で、これは最近の我々の技術でMusicMagusと呼んでいて、特定のここだと多分ピアノがギターになるのかなと思いますが、旋律は保ったまま音だけ変えることをやってます。

次に紹介するのはAutomatic Music Mixingです。各音が完成した後、それらをどのように混ぜるかを自動的に行います。人が最終的なミックスを行う際の初期状態を提供するため、作業が非常に楽になります。
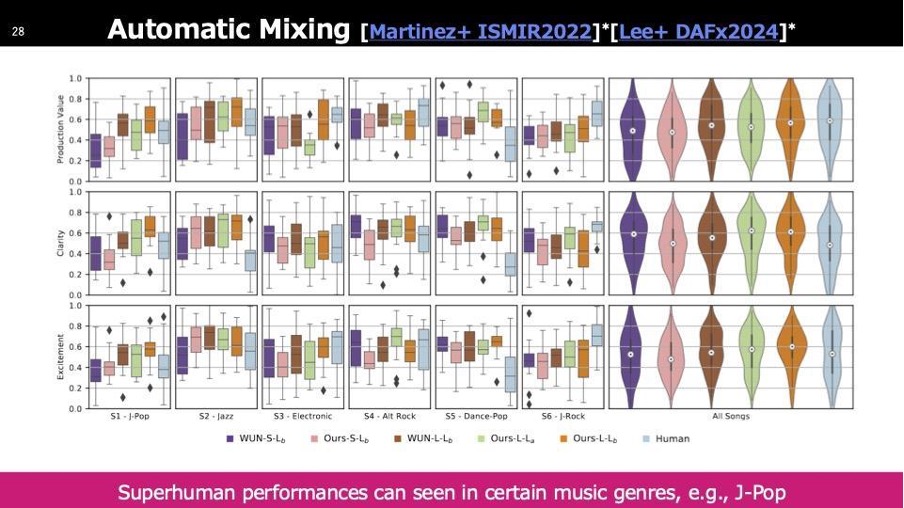
Mixingの質をこの環境で聴くことが難しいため、特にデモは用意していません。しかし、専門家を含む多くの方に聴いていただき、AIが作成したものと人がミックスしたものを様々な観点から評価しました。その結果、2022年時点で多くのジャンルにおいて、AIによるミックスが人のミックスを上回る成果を示しています。
これまでに説明したステップをすべて一つのモデルで実現する動きも見られます。多くのオンラインサービスが存在し、これらのサービスでは「このような曲が欲しい」とテキストで入力すると、音楽が出力される仕組みになっています。
出力がそのままステレオの楽曲になることは我々会社として問題視しています。代わりに、クリエイターのアシストツールとして役立つ技術の研究を行っており、「Diff-a-riff」と呼ばれる技術を開発しました。基本的には伴奏に歌を加えたり、歌に伴奏を追加したりする技術です。

さまざまなAIが存在する中で、Foundation Modelは基盤モデルとも呼ばれ、様々な機能の性能を底上げするモデルです。代表的なものにテキスト言語分野のGPTがあります。GPTは文章の要約やチャットなど多用途に使用でき、様々なアプリケーションの力を強化します。Music Foundation Modelも同様に、様々な機能の性能を向上させる役割を担っています。
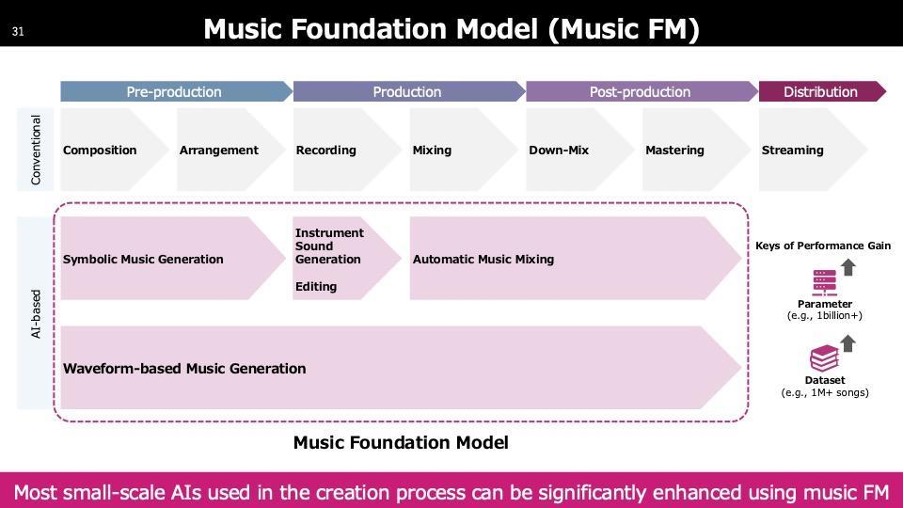
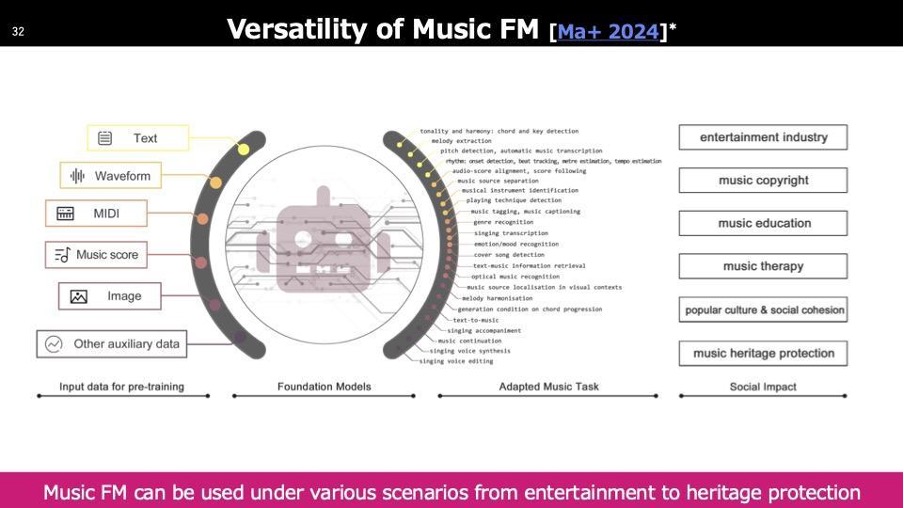
ここからFoundation ModelをMusicFMと呼びますが、さまざまな領域で探索されています。右側にリストされているものは論文で取り扱われているユースケースですが、エンターテインメント以外にも音楽教育、セラピー、文化保存など幅広い分野で利用されています。Foundation Modelという言葉はスタンフォードの教授が作りましたが、そのコンセプトは大規模なデータで学習し、様々なタスクに応用できる基盤モデルです。大量のデータは単一のモーダルに限定せず、左側にあるように利用可能な情報をすべて活用しています。
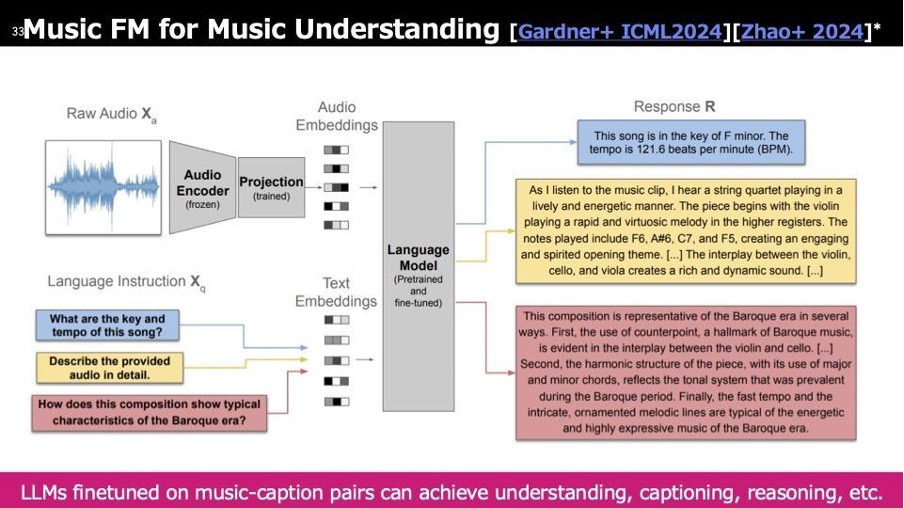
1つのFoundation Modelとして、先ほど「Understanding」というコンテンツの理解のための分野があるとお話ししましたが、そのためのMusic Foundation Modelがこちらです。これはSpotifyのLLarkというモデルからのスナップショットを取ったものです。具体的には、左上で音楽を入力すると、右側に以下のような情報が表示されます。
一番上には音楽そのものの音楽情報が出力されます。真ん中は「Captioning」と呼ばれており、画像のキャプションと同様に「この音楽ではどのようなことが起きているか」を示します。音楽の場合も同様に、楽曲内での出来事や特徴がキャプションとして表示されます。一番下は「Reasoning」と呼ばれ、なぜこのような楽曲になっているのかを様々な知識に基づいて説明します。
こうした機能があると、クリエイターが新たな作業を始めたいときに、元のコンテンツを改変したいけれども、コンテンツ自体の詳細情報をすぐに手に入れられない場合や失ってしまっているときに、このモデルを通すことで音楽から得られる情報を多方面から引き出し、そこからクリエイションをスタートできるため、非常に有用だと考えています。
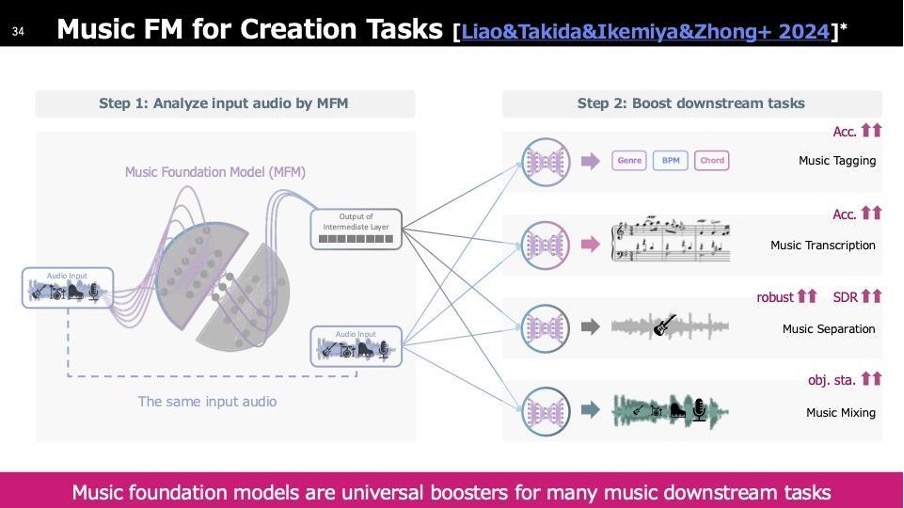
先ほど紹介したアプリケーションにはいくつか技術があります。上から「Tagging」は音楽にタグ付けする技術、2番目は「自動採譜」で音楽を入力するとスコアが生成されたり音源を分離したりします。これらはMixingの性能を向上させるモデルです。これらも当社の研究で開発したMusic Foundation Modelです。
Cinematicの分野では、OpenAIのSoraを皮切りに様々なビデオモデルが登場しています。次の課題として、現状では音が付いていない点があります。音が付いていても背景音楽のみで、画像との関連性がほとんどありません。クリエイションで画像を使用する際に音が伴わないことは少ないため、これが次の難しい課題だと考えています。

学習の方法は二つあります。1つ目は音と映像を一つのモデルで全て学習する方法です。もう1つは、それぞれのモーダルで学習した優れたモデル二つを使用して出力する方法です。通常、テキストプロンプトを二つのモデルに与えると、大まかな意味では適切なものが生成されますが、時間的にも空間的にも同期していない結果になります。これを解決し、画像と音がしっかりと同期した結果を出すのがComposableです。片方のモーダルで学習した優れたモデルを利用することで、最終的な結果が向上し、多くのところで注目されています。
少し宣伝になりますが、現在絶賛開催中のSounding Video Generation Challengeを開催中で、賞金も用意しています。このチャレンジでは、画像と音が時間的にどれだけ同期しているかを判定しランキングするタスクと、映像内のオブジェクトの位置に合わせて音も同じ位置から出るように空間的なアライメントを測るトラックがあります。3月頃まで開催しており、誰でも参加できます。
これは、全く音が付いていない動画をシステムに入力すると、音付きで出力されるものです。出力される音は一切元の素材を使用せず、AIがすべて生成しています。動画上部に「off」と表示されている場合は音がありません。この技術の良い例として、電車の音を生成する際に、電車が移動した後のドップラー効果もAIが反映して出力しています。
次はGame 分野です。先ほど説明した技術をモーション生成に活用しました。モーション生成は基本機能として存在しますが、学習したモデルを使用して、人が軌跡を指定すると、その方向に沿ってモーションを生成します。これにより、ゲームクリエイションで自由に軌跡に沿ってキャラクターを動かしたいときに、非常に役立ちます。
こちらはカナダで開催されているNeurIPSで発表されている「GenWarp」です。左側は入力画像で、この画像のみの情報から様々な他の視点の画像をAIが生成します。内部では3次元的な一貫性が保たれるように設計されています。具体的には、画像を異なる角度から見た形に歪ませ、その際に発生するOclusion(本来裏側にあり見えなかった部分)をAIが生成しています。ここまでがApplication Researchです。

ステップ3:Software Development(ソフトウェア開発)
次にSoftware Developmentについて、具体的な話よりも一般的な話をします。技術者同士では常識となっているツールやフォーマットが、クリエイターの方々が実際に使用する際には使いづらかったり、コミュニケーションがうまく取れなかったりすることがよくあります。
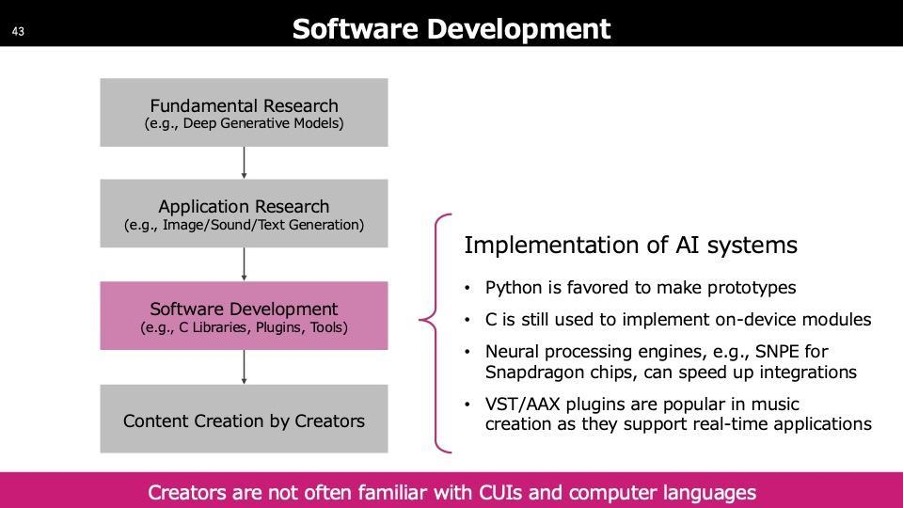
内部ではまずエンジニアリングを行い、先ほどの技術を使える形に整えてクリエイターに提供します。最初は思ったのと異なる、使いづらい、質が足りない、期待と違うなどのフィードバックがほぼ99%の確率で寄せられます。それを受けて改良し、再度提供するというフィードバックループが必ず存在します。一発で終わることはほとんどありません。
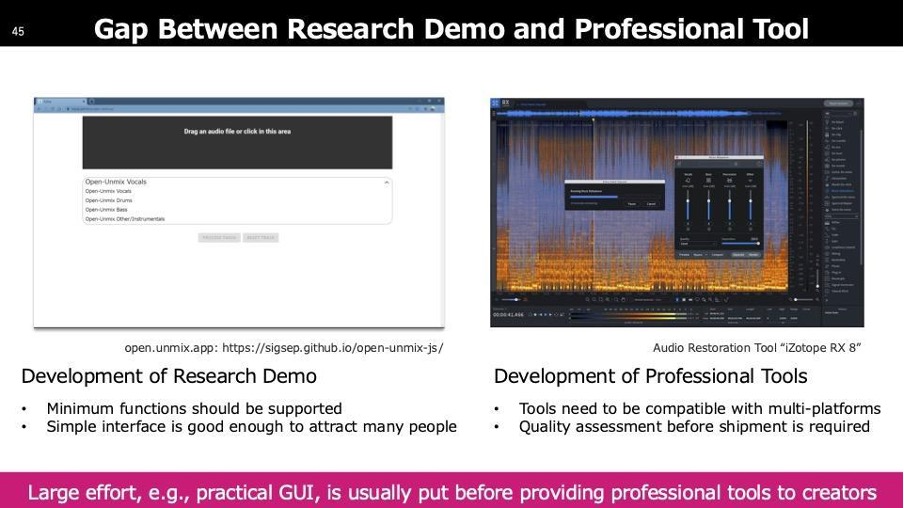
我々が「ツール」と呼んでいるものと、クリエイターの方々が呼んでいるツールは大きく異なります。左側はAI研究者が作りがちなツールで、機能を実現するための最低限のUIしか備えていません。一方、クリエイターが使用するツールは、自分の環境に合わせて使いやすくする必要があります。クリエイターは、本筋でない部分に時間を割いて、使い方を学ぶことは避けたいので、右側のようなツールが提供されます。
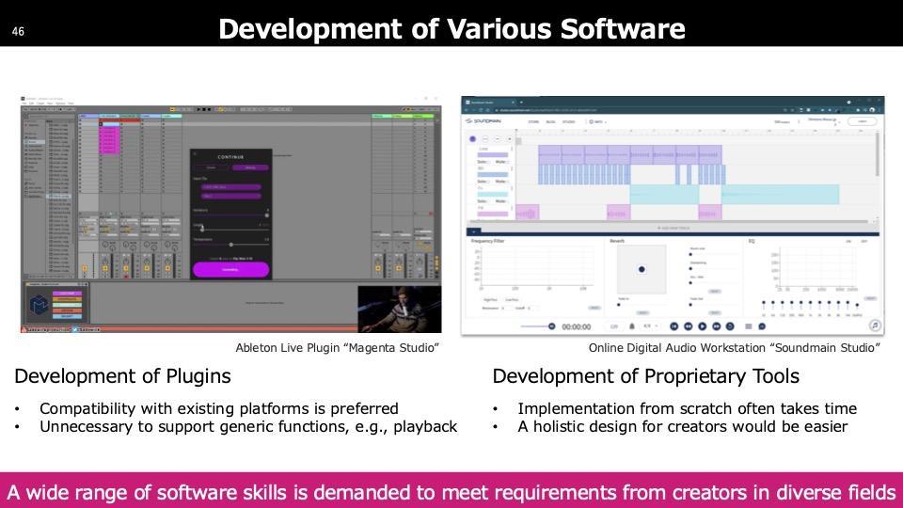
我々や他のグループは、既存のソフトウェアに最低限の機能を持つプラグインとして提供する方法を採用しています。もう一つの方法は、全てを丸ごと作成して提供するもので、こちらは少し壮大ですが、それぞれに長所と短所があります。必要な機能やタイムラインに応じて、どちらのアプローチを取るかが分かれます。
ステップ4:Content Creation by Creators(クリエイターによる作品制作)
ここから先は具体的な話をしていきます。
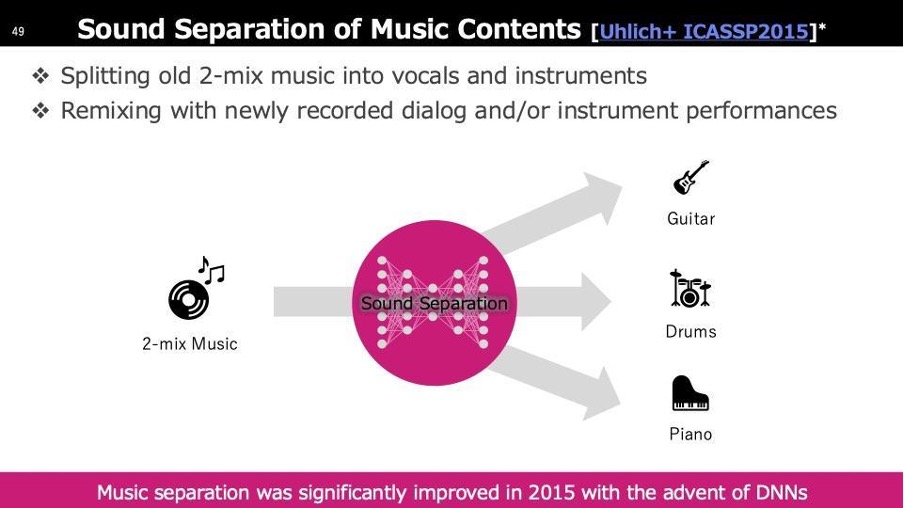
ユースケース1「Sound Separation(音源分離)」
音源分離技術は実は1990年代、さらに前から存在しています。難しさを例えると、ミックスジュースを元の単独のジュースに戻すことですが、このことを「ミックスジュース問題」と呼ぶこともあります。2015年に大きな進展がありました。それまで機械学習で深層学習を用いないアプローチが使われていた中、我々が深層学習を音楽の分離に初めて応用しました。この結果、性能が飛躍的に向上し、2チャンネルの音楽からギターやドラム、ピアノを抜き出すことが可能になりました。
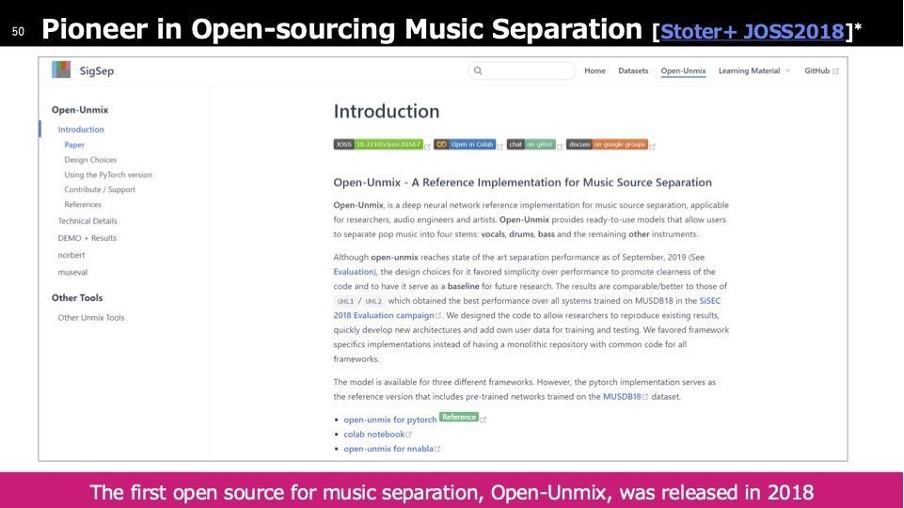
その後、パイオニアとして2018年にオープンソース化を実施しました。音楽分離技術のリファレンス手法を公開し、多くの技術者がこれを基に開発を進めています。オープンソースの目的としてはそれが本来だと思うのですが、この時代ではそこまでメジャーではありませんでした。
少し前にチャレンジについてお話ししましたが、私はチャレンジマニアでして、これまでも様々な取り組みを行ってきました。最初に実施したのが2021年のクラウドベースのチャレンジで、音源分離チャレンジと呼ばれるものでした。このチャレンジでは、評価システムを構築し、ソニー・ミュージックエンタテインメント(SMEJ)がこのために作成した音楽をどれだけ綺麗に分離できるかを競いました(左側)。
その後、さらに進化させたのがCinematic Demixing Trackで、ソニー・ピクチャーズエンタテインメントの映画から作成したデータセットを用い、それらの音源をどれだけ正確に分離できるかを競うチャレンジでした(右側)。
こうした活動を続けていますが、メリットが伝わりにくいこともあります。しかし、このような取り組みを行うことで、技術レベル全体が底上げされるのが大きな利点です。実際、過去2回のチャレンジを通じて技術の向上が見られました。また、グループ会社にソニー・ミュージックグループがあるため、クリエイションの現場での活用も視野に入れていました。これまでスタジオに技術を持ち込み、「クオリティはどうか」「このプロセスでどの程度の精度が必要か」といったフィードバックループを繰り返しました。そして、2020年に初めて音源分離技術が商用利用可能と判断され、実際に導入されました。表立っては言われていませんが、現在では音源分離技術が多くの現場で活用されているはずです。

「60-Year Time Travel」というプロジェクトでは、カナダの有名なピアニスト、グレン・グールドのピアノパフォーマンスに朗読が組み合わさった音源がありました。俳優の石丸幹二さんが日本語版を制作したいと考えていましたが、グールドはすでに亡くなっており、共演は不可能でした。また、当時の音源にはピアノと朗読が混ざっており、分離する手段がなかったため、長年実現できずにいました。
音源分離技術を使えば実現できるかもしれないということで、プロジェクトが進められました。左側の写真は1961年にニューヨークで録音された当時の様子ですが、当時はマルチトラック録音の技術がなく、すべての楽器や音声を一斉に録音するしかありませんでした。一応、擬似的なマルチトラックのように仕切りを設け、マイクの配置を工夫していましたが、それでも音が漏れ込んでしまっていました。
この漏れ込みを音源分離技術によってすべて除去しました。結果として、朗読部分を取り除き、ピアノの音だけを残すことができました。その上に、石丸幹二さんの日本語朗読を重ねることで、新たな形での共演が実現しました。

この作品はCDとして発売されており、ご購入いただけると思います。アルバムのカバーには、石丸幹二さんの写真の位置に、本来の朗読を担当していた方の写真が配置され、オマージュとしてデザインされていると聞いています。動画の構成としては、まず元のコンテンツが流れ、その後、音源分離技術によって抽出されたピアノ音源が再生され、最後に石丸幹二さんの朗読が重ねられたバージョンが流れる形になっています。
ユースケース2「Sound Effect Generation」
次はSound Effect Generationについてです。これは、最初に触れたワンステップでの画像生成技術を応用したもので、Machine Learningのコアな部分として論文を発表しました。画像は最も取り扱いやすいモーダルであり、ワンステップ生成を実現しましたが、今年は音に対しても同様の試みを進めてきました。その成果をICLRという学会に投稿し、査読結果も良好だったため、良い評価が得られるのではないかと期待しています。)
(実際に採択されました)
この技術では、サウンドのワンステップ生成を実現しました。指標としてRTF(Real Time Factor)を用いており、これは例えば10秒の音を生成するのにかかった時間が10秒以内であればリアルタイム処理が可能という意味になります。例えば、RTFが0.69と記載されている場合、10秒の音を6.9秒で生成できることを示し、リアルタイム以下で処理できます。これにより、次のセグメントの処理が再生中に完了し、待ち時間なくシームレスに音を生成できる仕組みになっています。
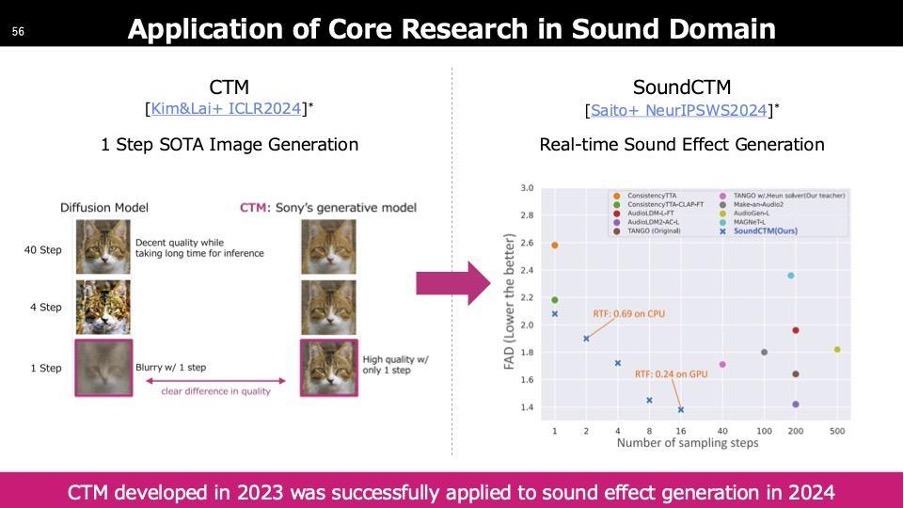
CPUで0.69でGPUで0.24、このGPUが何かにもよるのですが、一般的なCPUの方は一般的なラップトップでも使えわれているようなCPUでこれが実現できました。

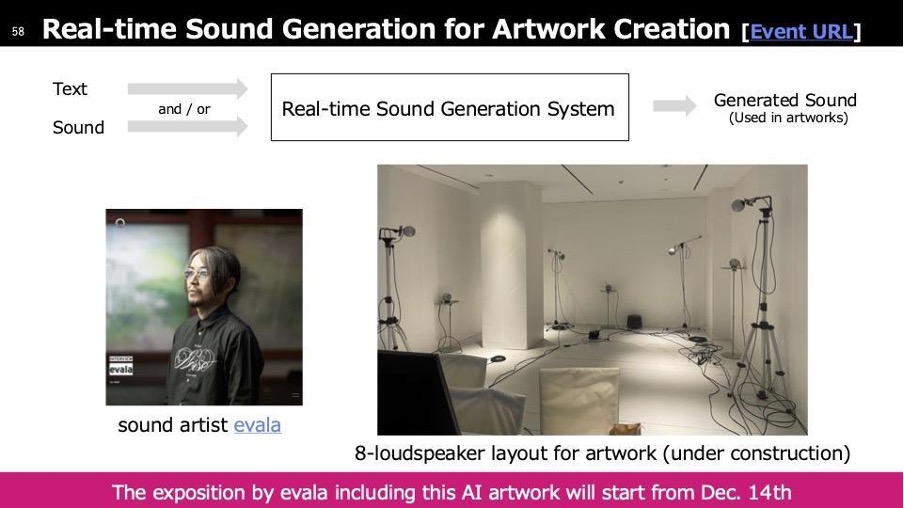
宣伝のようになってしまいますが、evalaというサウンドアーティストの展示が12月14日から開催されます。この展示では、リアルタイムの音生成技術が活用されています。作品の特徴としては、彼が制作した音に対して特定の音を外挿する形で無限に音が生成される仕組みになっています。その無限に生み出される音がどのようなものを作り出すのかを探る試みです。写真はまだ完成前のものですが、8個のスピーカーを使用していることがわかるようになっています。展示で流れている音には、先ほど紹介したクリエイションのステップで開発された技術が使われています。
生成AI時代にどのようにしてクリエイターを守っていくのか
AIをクリエイションに活用する際には慎重に進めるべき課題が多く存在します。これまでAIの良い面を紹介してきましたが、実際に導入する際には法的な問題や倫理的な問題を解決した上で進める必要があります。
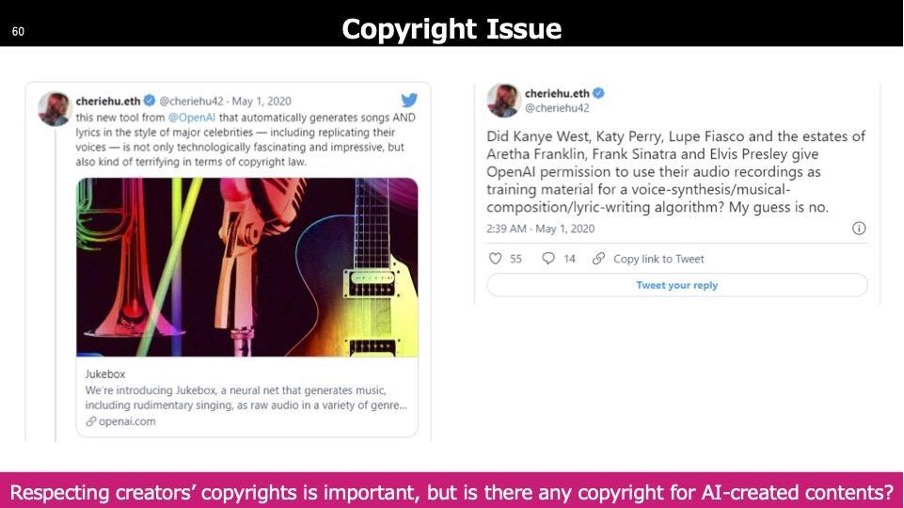
著作権の問題として、まず学習データと著作物の関係が挙げられます。著作物には適切な権利が付与されており、本来は想定外の用途で無断使用されないように保護されています。音楽業界では、著作物を利用する際に適切な対価が発生する仕組みが整っています。しかし、生成AIが著作物を学習し、それに近いものを生成することで元の著作物と競争関係になってしまう問題が発生しています。特に、最近ではテキスト入力だけで高品質な楽曲が生成できるAIが登場し、学習元となった楽曲が著作権を持つ作品である場合の法的リスクが指摘されています。
また、AIが生成したコンテンツに著作権が認められるかどうかも重要な課題です。これは、学習データの著作権問題とは異なる論点です。現状、多くの国では人が介在しない生成物には著作権が発生しないとされています。そのため、AIによって生成された作品が第三者によって無断で使用された場合でも、著作権を行使することができないという問題が生じます。これにより、生成AIを用いたコンテンツが不正利用されても法的に保護できないリスクがあるのです。
こちらは著作権の問題に近い話ですが、生成AI自体が抱える課題の一つです。特にDiffusionモデルで顕著な問題として、生成AIは本来、学習セットの概念を抽象的に学習し、新しい出力を生成することが求められます。しかし、最近の研究では、学習セットの一部をニューラルネットワークの係数としてそのまま記憶してしまう現象が問題視されています。このような技術が広まると、学習セットそのものがそのまま出力される可能性があり、これは誰もが避けるべき状況です。この現象は「Memorization」と呼ばれ、学習時に起こるものですが、これを防ぐ技術開発が進められています。Memorizationが起こらないように適切な学習を行うことは、生成AIを開発する側の責任であると考えています。

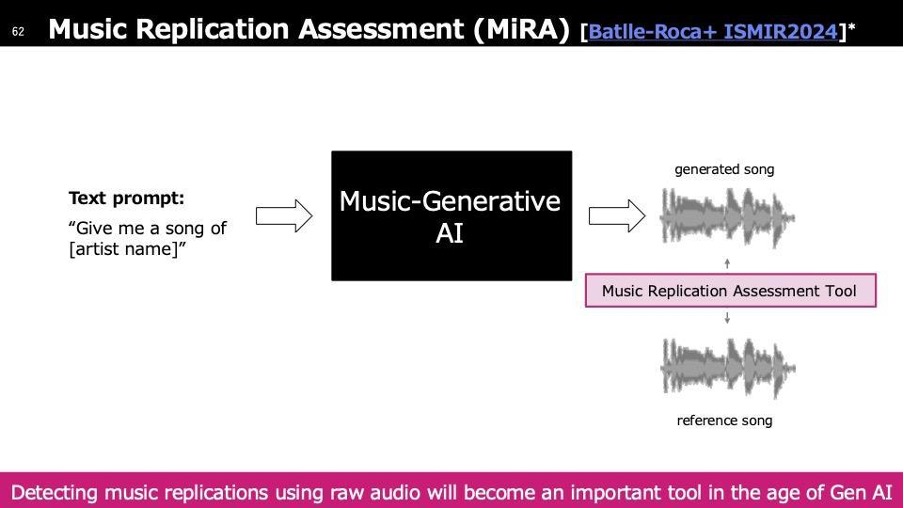
これは音楽のケースとして考えていただければと思います。AIが生成した楽曲の出力が、既存の楽曲に似ている場合、その類似性を定量化し、無断使用の可能性を特定する技術が求められます。そのために開発されたのがMusic Replication Assessment Toolです。
このツールでは、楽曲の特徴量を解析し、「どこがどの程度似ているのか」を明確に示すことができます。音楽領域において、こうした技術は今後ますます必要になってくると考えられます。なぜなら、Attribution(帰属)の問題があるからです。Attributionとは、「この楽曲はこの作曲者によるものだ」と明確にする仕組みで、作品が多く聴かれるほど、その作曲者が適切な収入を得られるようになっています。
しかし、生成AIが作り出した楽曲が何を元にしているのか分からない場合、Attributionが曖昧になり、本来クリエイターが得るべき収益を適切に分配できなくなります。これにより、たとえ多くのAI生成楽曲に影響を与えていたとしても、元のクリエイターが収益を得られず、逆にほとんど使用されていない楽曲の提供者が等分配で収入を得てしまう可能性が生じます。こうした問題を解決するためにも、生成された楽曲と既存の楽曲の類似度を解析し、どの部分がどの程度似ているかを明確にする技術が重要になってきます。
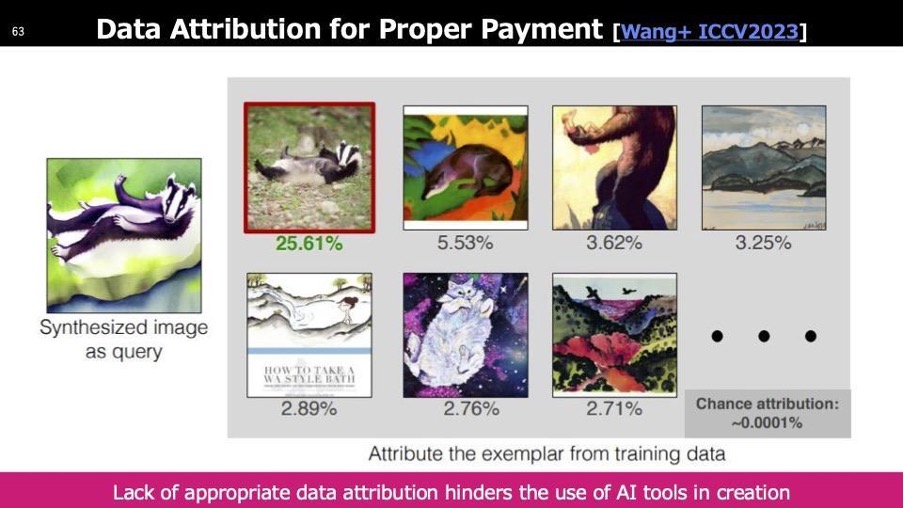
これが先ほどお話ししたData Attributionの問題です。音の場合は説明が難しいのですが、ここでは画像を例に説明します。理想的には、「この画像が生成結果に対して何%寄与しているか」をパーセンテージで示せるようになることが求められます。
もしこの寄与度の特定ができなければ、最終的にすべて等分配するしかなくなり、本来の貢献度に応じた適切な報酬分配ができなくなります。Data Attributionは現在もオープンな課題として研究が進められており、音楽や画像など、生成AIが関わるあらゆる領域で重要なテーマとなっています。
Q&A

こちらでお話しする内容は以上です。何か質問やコメントがあれば、お聞かせください。
参加者: 貴重なお話をありがとうございました。私は社会人学生で、インターネットとエンターテインメントに関わる仕事をしています。Automatic Mixingのスライドに、HIPHOPなどのジャンルごとにAIと人間を比較した図があったように思います。AIと人間の作る音楽の違いに興味があるのですが、特にAIに任せると良い結果が得られるジャンルはありますか?
光藤: 研究の結果を見ると、ジャズなどは比較的良いスコアが出ています。一方でJ-ロックのようなジャンルはAIのスコアが低めです。これは学習データの偏りも影響しているかもしれません。ただし、この研究はジャンルごとの傾向を明確にすることが目的ではないため、一概には言えませんが、そうした傾向があるのは確かです。
参加者: 貴社の場合、ソニーミュージックやソニーピクチャーズなどエンターテインメント関連のグループ会社がありますが、この研究結果を相互に活用するような取り組みはありますか?
光藤: 今回の研究自体は直接そうした取り組みではありませんが、他のプロジェクトでは連携しています。ソニー・ミュージックエンタテインメントの本社はニューヨークにあり、私が現在ニューヨークにいるのもその関係です。技術の活用についてさまざまな議論を行いながら、どういった技術で課題を解決できるかを模索しています。グループ会社にエンタメ企業がある強みを活かして、さまざまな連携が行われています。
参加者: 本日の講義、ありがとうございました。インポートした音の質感や音色を変える機能について質問です。例えば、インポートしたピアノの音色をキープしながら、リズムや雰囲気を変えるといった機能を持つ、商品化されたAIツールはありますか?
光藤: 一般化されている技術としては存在しますが、我々が商品として提供しているものは今のところありません。
参加者: ビデオからのサウンド生成が正確に行われていることは理解しましたが、テキストからのサウンド生成の質はどの程度でしょうか?また、両者の違いは何ですか?
光藤: ユースケース2でお話ししたのが、テキストを入力してサウンドを生成する技術です。質については、評価基準が複数あるため単純には言えませんが、私たちの分野では、元の音とAI生成の音、さらに他のツールで生成した音を比較し、聴感評価を行います。論文でもこの評価を行いますが、最近の結果を見る限り、既に非常に高いクオリティに達していると考えています。以前はサンプリングレートが低めのフォーマットで生成されるのが一般的でしたが、現在では映画などで使用される高品質なサンプリングレートでの生成が可能になり、実用レベルに達しているといえます。
参加者: つまり、脚本や台本のようなテキストデータから、納得のいくサウンドが生成されるという理解でよろしいでしょうか?
光藤: その理解で概ね正しいと思います。ただし、「Text to Sound」という技術にはさまざまな解釈があります。一つは、特定の音素材を直接出力するモデル、もう一つは、スクリプトを理解してそのコンテキストに合ったサウンドを作るモデルです。前者は比較的実現しやすく、既に高品質な生成が可能になっています。一方、後者は高度なコンテキスト理解が求められるため、まだ発展の余地がある分野です。
参加者: AI for Creatorのテーマについて、技術が日進月歩で進化する中で、AIとクリエイターの関係そのものが変化していくと考えています。今後、純粋にクリエイターの権利を守ることが難しくなるのではないかと感じています。研究の視点から、5年後や10年後を見据えた考え方があれば教えてください。
光藤: 私たちが想定する最悪のシナリオは、AIがクリエイションを完全に代替してしまうことです。もしそうなれば、音楽業界を含め、エンターテインメント産業全体が機能しなくなってしまいます。そのため、そうした状況にならないよう、どのような仕組みが必要かを考えています。現在は、3〜5年以内に大きな変革が起こることを見据え、そのタイムラインに合わせた研究開発を進めています。
参加者: 筧研究室の学生です。ゲームで使われるアテレコのように、リアルタイムで効果音を生成する事例は既にあるのでしょうか?例えば、ゲームのサウンドデザインで、AIが自動生成した音を活用している例などはありますか?
光藤: 私自身は詳しくないですが、もしかすると既にそうした技術が使われているかもしれません。ただ、現在の技術水準を考えると、まだ完全には実用化されていない可能性が高いと思います。ただし、この1〜2年で前衛的なゲームスタジオがAIを活用した音響デザインを採用し、実際にゲームで使用するケースは十分に考えられます。技術的には、リアルタイム生成が可能な段階に達しています。
参加者: 先ほど「2〜3年でAIによるクリエイションが人間を超える」とおっしゃっていましたが、シンギュラリティのような技術的特異点が2035年頃に訪れるという話もあります。クリエイションの分野では、それよりも早く人間を超える可能性があるのでしょうか?
光藤: 2〜3年でAIのクリエイションが完全に人間を超えるとは考えていません。むしろ、AIが作った音楽やコンテンツが市場に浸透し始めており、その影響をクリエイターが受けることを想定しています。クリエイターが適切に収益を得られる仕組みが、この2〜3年の間に整備されなければならないと思います。シンギュラリティについては、生成AIの発展がどのような影響を与えるか予測が難しいですが、短尺の映像コンテンツから広告、ドラマ、映画、そして最終的にはインタラクティブなゲーム領域に波及すると考えています。ただし、3年前には想像できなかった技術も登場しているため、予測するのは難しい部分もあります。
参加者: CFIのプロジェクトに関わっています。AIが関与する領域の一つとしてアートセラピーがあると思うのですが、AIとアートセラピーが今後、または現在どのように関わっているのかについてお聞きしたいです。
光藤: 私も関与している論文があり、これはサーベイ論文ですが、Music Foundation Modelがどのような技術で構成されているか、また、それがどのように活用できるかを整理したものです。論文の中では、AIによるミュージックセラピーの可能性についても触れられています。具体的な内容については、その論文を読んでいただくのが最も正確ですが、私の考えとしては、音楽の生成(Generation)というと、多くの人はポップソングをイメージするかもしれません。しかし、AIはヒーリング音楽のようなものも生成できます。
例えば、リアルタイムの音楽生成技術がセラピーの分野に応用できると仮定すると(実際にはすでに可能ですが)、AIが個人の状態を認識しながら音楽をリアルタイムに生成し、さらにその人の反応や改善状況をモニタリングしながら、音楽の構成を動的に変えていくことができるかもしれません。これは従来の技術では実現が難しかった領域ですが、今後、こうしたAI技術がアートセラピーの分野でも活用される可能性があると考えています。
参加者: 私の質問の背景には、共同研究者であるミュージックセラピーの専門家のデモを見たことがあります。そこでは、発話をしない方が音楽を介して対話を行うシーンがありました。それをAIが今後どのように関わっていくのかが気になって質問しました。今のお答えを聞いて、AIが関与することで、そうした対話の可能性がさらに広がるかもしれないと期待できると思いました。
小薮: どうもありがとうございました。まだまだ質問は尽きないかと思いますが、時間となりましたので、Creative Futurists Dialogues 第7回をこれにて終了いたします。